Test symmetries with sklearn decision tree models
Setup
Begin from an environment with a recent version of python 3.
source setup.sh
Leave the environment with deactivate. Clean up fully by removing env/.
Run examples
make
Begin from an environment with a recent version of python 3.
source setup.sh
Leave the environment with deactivate. Clean up fully by removing env/.
make
Highly interpretable, sklearn-compatible classifier based on decision rules This is a scikit-learn compatible wrapper for the Bayesian Rule List class
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
Data Efficient Decision Making
MBTR is a python package for multivariate boosted tree regressors trained in parameter space.
implementation of machine learning Algorithms such as decision tree and random forest and xgboost on darasets then compare results for each and implement ant colony and genetic algorithms on tsp map, play blackjack game and robot in grid world and evaluate reward for it
🤖 Interactive Machine Learning experiments: 🏋️models training + 🎨models demo
pyGAM Generalized Additive Models in Python. Documentation Official pyGAM Documentation: Read the Docs Building interpretable models with Generalized
Time series analysis today is an important cornerstone of quantitative science in many disciplines, including natural and life sciences as well as eco
Auto_TS: Auto_TimeSeries Automatically build multiple Time Series models using a Single Line of Code. Now updated with Dask. Auto_timeseries is a comp
First version to go on Zenodo 🤖 second major version ♊
Source code(tar.gz)learn python in 100 days, a simple step could be follow from beginner to master of every aspect of python programming and project also include side project which you can use as demo project for your
MLOps The MLOps is the process of continuous integration and continuous delivery of Machine Learning artifacts as a software product, keeping it insid
Streamlit Demo: Uber Pickups in New York City A Streamlit demo written in pure Python to interactively visualize Uber pickups in New York City. View t
img2palette Turning images into '9-pan' palettes using KMeans clustering from sklearn. Requirements We require: Pillow, for opening and processing ima
Kaggler is a Python package for lightweight online machine learning algorithms and utility functions for ETL and data analysis. It is distributed under the MIT License.
changepy Changepoint detection in time series in pure python Install pip install changepy Examples from changepy import pelt from cha
Machine Learning Videos This is a collection of recorded talks at machine learning conferences, workshops, seminars, summer schools, and miscellaneous
hexhamming What does it do? This module performs a fast bitwise hamming distance of two hexadecimal strings. This looks like: DEADBEEF = 1101111010101
liquid_scikit_learn Scikit learn library models to account for data and concept drift. This python library focuses on solving data drift and concept d
I have collected data about a set of patients, all of whom suffered from the same illness. During their course of treatment, each patient responded to one of 5 medications, Drug A, Drug B, Drug c, Dr
Exemplary lightweight and ready-to-deploy machine learning project
This is the material used in my free Persian course: Machine Learning with Python
SHAP (SHapley Additive exPlanations) is a game theoretic approach to explain the output of any machine learning model. It connects optimal credit allo
Decision-Threshold-ML Tutorial for improve skills: 'Decision Threshold In Machine Learning' (from GeeksforGeeks) by Marcus Mariano For more informatio
fastdtw Python implementation of FastDTW [1], which is an approximate Dynamic Time Warping (DTW) algorithm that provides optimal or near-optimal align
HPOflow - Sphinx DOC Tools for Optuna, MLflow and the integration of both. Detailed documentation with examples can be found here: Sphinx DOC Table of
Telco Customer Churn Prediction - Plotly Dash Application Description This dash application allows you to predict telco customer churn using machine l
Code Repository for Machine Learning with PyTorch and Scikit-Learn
Toolkit for Building Robust ML models that generalize to unseen domains (RobustDG) Divyat Mahajan, Shruti Tople, Amit Sharma Privacy & Causal Learning
Reproducibility and Replicability of Web Measurement Studies This repository holds additional material to the paper "Reproducibility and Replicability
 482 Nov 19, 2022
482 Nov 19, 2022
 6.9k Jan 5, 2023
6.9k Jan 5, 2023

 197 Jan 6, 2023
197 Jan 6, 2023
 61 Dec 19, 2022
61 Dec 19, 2022
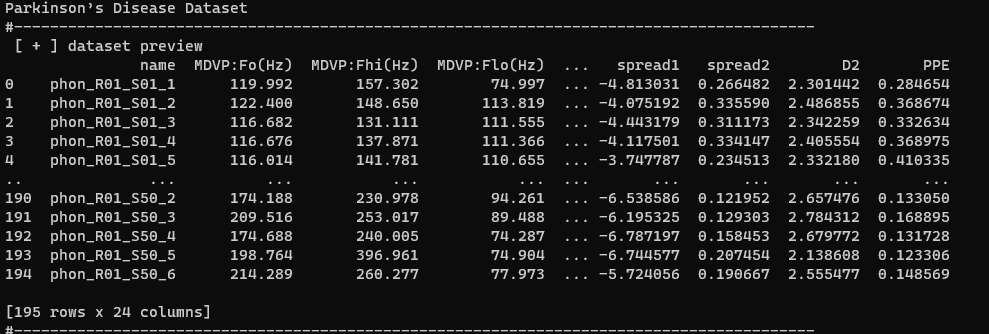
 1 Jan 19, 2022
1 Jan 19, 2022

 1.4k Jan 6, 2023
1.4k Jan 6, 2023
![[HELP REQUESTED] Generalized Additive Models in Python](https://github.com/dswah/pyGAM/raw/master/imgs/pygam_tensor.png)
 747 Jan 5, 2023
747 Jan 5, 2023
 129 Dec 24, 2022
129 Dec 24, 2022
 519 Jan 3, 2023
519 Jan 3, 2023

 6 Nov 05, 2022
6 Nov 05, 2022
 25 Nov 27, 2022
25 Nov 27, 2022
 230 Dec 28, 2022
230 Dec 28, 2022
 2 Jan 01, 2022
2 Jan 01, 2022
 720 Dec 25, 2022
720 Dec 25, 2022
 92 Nov 08, 2022
92 Nov 08, 2022
 1.5k Dec 29, 2022
1.5k Dec 29, 2022
 12 Oct 14, 2022
12 Oct 14, 2022
 7 Nov 18, 2021
7 Nov 18, 2021
 1 Jan 28, 2022
1 Jan 28, 2022
 6 Dec 20, 2022
6 Dec 20, 2022
 4 Aug 07, 2022
4 Aug 07, 2022
 18.2k Jan 02, 2023
18.2k Jan 02, 2023
 0 Jan 20, 2022
0 Jan 20, 2022
 651 Jan 04, 2023
651 Jan 04, 2023
 17 Nov 20, 2022
17 Nov 20, 2022
 3 Nov 20, 2021
3 Nov 20, 2021
 1.4k Jan 03, 2023
1.4k Jan 03, 2023
 6 Dec 31, 2022
6 Dec 31, 2022