Machine Learning Algorithms ( Desion Tree, XG Boost, Random Forest ) required packages: numpy,pandas,sklearn,xgboost
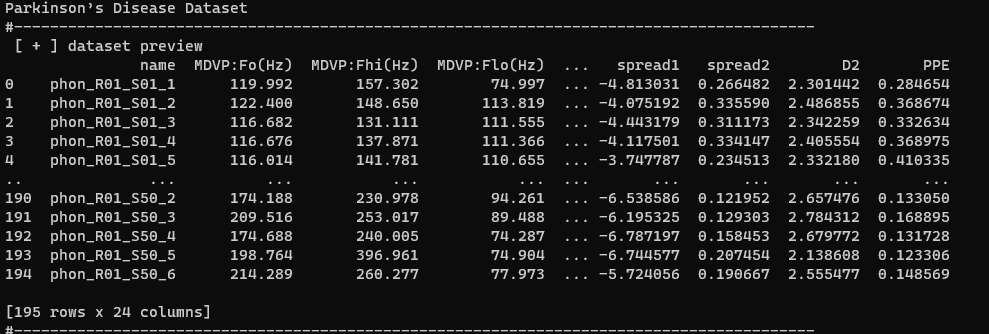

Ant Colony On TSP

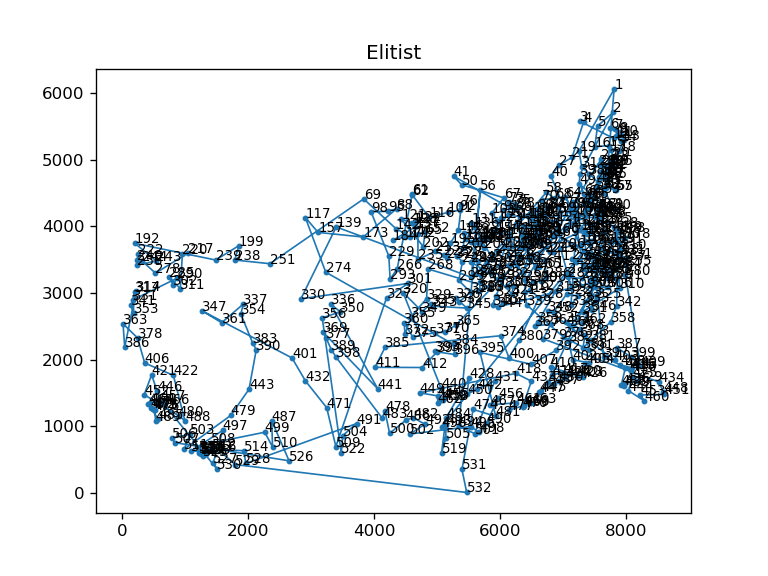

Genetic Algorithm on TSP
Sample run in jetbrains Pycharm

Blckjack game

Robot in gridworld

English | 简体中文 AutoX是什么? AutoX一个高效的自动化机器学习工具,它主要针对于表格类型的数据挖掘竞赛。 它的特点包括: 效果出色: AutoX在多个kaggle数据集上,效果显著优于其他解决方案(见效果对比)。 简单易用: AutoX的接口和sklearn类似,方便上手使用。
timeseries-generator This repository consists of a python packages that generates synthetic time series dataset in a generic way (under /timeseries_ge
AutoTS AutoTS is a time series package for Python designed for rapidly deploying high-accuracy forecasts at scale. There are dozens of forecasting mod
Implemented four supervised learning Machine Learning algorithms from an algorithmic family called Classification and Regression Trees (CARTs), details see README_Report.
An open-source, low-code machine learning library in Python 🚀 Version 2.3.5 out now! Check out the release notes here. Official • Docs • Install • Tu
30 Days Of Streamlit 🎈 This is the official repo of #30DaysOfStreamlit — a 30-day social challenge for you to learn, build and deploy Streamlit apps.
It selects the best indexing parameters to achieve the highest recalls given memory and query speed constraints.
K Means Algorithm What is K Means This algorithm is an iterative algorithm that partitions the dataset according to their features into K number of pr
Time series analysis today is an important cornerstone of quantitative science in many disciplines, including natural and life sciences as well as eco
The unified machine learning framework, enabling framework-agnostic functions, layers and libraries. Contents Overview In a Nutshell Where Next? Overv
2021 Machine Learning Security Evasion Competition This repository contains code samples for the 2021 Machine Learning Security Evasion Competition. P
fastdtw Python implementation of FastDTW [1], which is an approximate Dynamic Time Warping (DTW) algorithm that provides optimal or near-optimal align
Domino Research This repo contains projects under active development by the Domino R&D team. We build tools that help Data Scientists and ML engineers
seqlearn seqlearn is a sequence classification toolkit for Python. It is designed to extend scikit-learn and offer as similar as possible an API. Comp
(intron I nterrogator and C lassifier) intronIC is a program that can be used to classify intron sequences as minor (U12-type) or major (U2-type), usi
Prince is a library for doing factor analysis. This includes a variety of methods including principal component analysis (PCA) and correspondence anal
hexhamming What does it do? This module performs a fast bitwise hamming distance of two hexadecimal strings. This looks like: DEADBEEF = 1101111010101
Organic Alkalinity Sausage Machine A Python toolbox to churn out organic alkalinity calculations with minimal brain engagement. Getting started To mak
偷鸡不成项目集锦 坦率地讲,涉及金融市场的好策略如果公开,必然导致使用的人多,最后策略变差。所以这个仓库只收集我目前失败了的案例。 加密货币组合套利 中国体育彩票预测 我赚不上钱的项目,也许可以帮助更有能力的人去赚钱。
Streamlit Demo: Uber Pickups in New York City A Streamlit demo written in pure Python to interactively visualize Uber pickups in New York City. View t

 431 Dec 28, 2022
431 Dec 28, 2022
 87 Dec 20, 2022
87 Dec 20, 2022
 652 Jan 03, 2023
652 Jan 03, 2023
 0 Jan 31, 2022
0 Jan 31, 2022
 6.7k Jan 08, 2023
6.7k Jan 08, 2023
 53 Jan 02, 2023
53 Jan 02, 2023
 419 Jan 01, 2023
419 Jan 01, 2023
 1 Nov 01, 2021
1 Nov 01, 2021
 129 Dec 24, 2022
129 Dec 24, 2022
 8.2k Dec 31, 2022
8.2k Dec 31, 2022
 8 May 01, 2022
8 May 01, 2022
 651 Jan 04, 2023
651 Jan 04, 2023
 73 Oct 17, 2022
73 Oct 17, 2022
 653 Dec 27, 2022
653 Dec 27, 2022
 4 Jul 26, 2022
4 Jul 26, 2022
 915 Dec 31, 2022
915 Dec 31, 2022
 12 Oct 14, 2022
12 Oct 14, 2022
 1 Feb 01, 2022
1 Feb 01, 2022
 28 Dec 29, 2022
28 Dec 29, 2022