poseWrangler
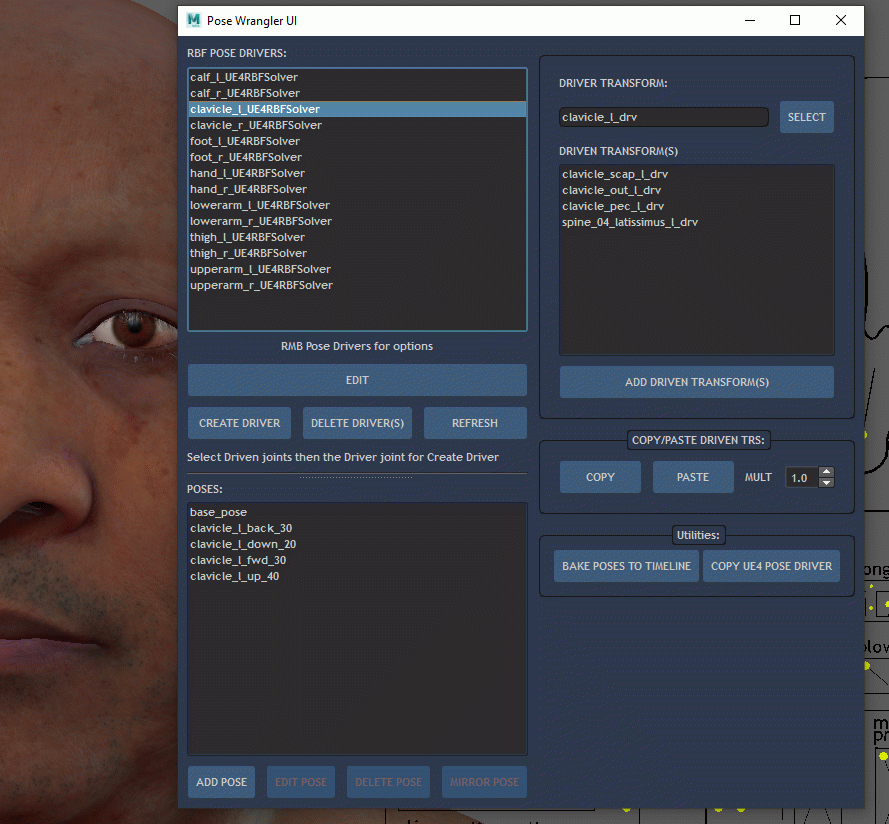
Overview
PoseWrangler is a simple UI to create and edit pose-driven relationships in Maya using the MayaUE4RBF plugin. This plugin is distributed by Epic Games and installed by Quixel Bridge, initially with MetaHuman source files.
Initially created by Chris Evans, maintained, improved and prettied-up throughout MetaHuman development by Judd Simantov.
Opening the tool
To load the tool, you can call it like so:
from poseWrangler import poseWranglerUI as ui
ui.showUI()

 26 Dec 14, 2022
26 Dec 14, 2022

 22 Nov 13, 2022
22 Nov 13, 2022
 34 Sep 8, 2022
34 Sep 8, 2022
 513 Jan 3, 2023
513 Jan 3, 2023

 45 Oct 4, 2022
45 Oct 4, 2022

 673 Dec 28, 2022
673 Dec 28, 2022
 1.4k Dec 29, 2022
1.4k Dec 29, 2022

 1k Dec 30, 2022
1k Dec 30, 2022




 55 Dec 29, 2022
55 Dec 29, 2022
 1 Mar 11, 2022
1 Mar 11, 2022
 5k Jan 02, 2023
5k Jan 02, 2023
 5.3k Jan 04, 2023
5.3k Jan 04, 2023
 43 Nov 28, 2022
43 Nov 28, 2022
 284 Nov 25, 2022
284 Nov 25, 2022
 5 Oct 24, 2022
5 Oct 24, 2022
 1 Jan 11, 2022
1 Jan 11, 2022
 65 Dec 12, 2022
65 Dec 12, 2022
 214 Nov 24, 2022
214 Nov 24, 2022
 5 Nov 23, 2022
5 Nov 23, 2022
 1.1k Jan 01, 2023
1.1k Jan 01, 2023
 13.8k Jan 02, 2023
13.8k Jan 02, 2023
 1 Feb 01, 2022
1 Feb 01, 2022
 16 Dec 09, 2022
16 Dec 09, 2022
 3 Oct 15, 2021
3 Oct 15, 2021
 4 Feb 27, 2022
4 Feb 27, 2022
 382 Jan 07, 2023
382 Jan 07, 2023
 6 Apr 29, 2022
6 Apr 29, 2022
 1.1k Jan 03, 2023
1.1k Jan 03, 2023