BlobCity AutoAI
A framework to find the best performing AI/ML model for any AI problem. Works for Classification and Regression type of problems on numerical data. AutoAI makes AI easy and accessible to everyone. It not only trains the best-performing model but also exports high-quality code for using the trained model.
The framework is currently in beta release, with active development being still in progress. Please report any issues you encounter.
Getting Started
pip install blobcity
import blobcity as bc
model = bc.train(file="data.csv", target="Y_column")
model.spill("my_code.py")
Y_column is the name of the target column. The column must be present within the data provided.
Automatic inference of Regression / Classification is supported by the framework.
Data input formats supported include:
- Local CSV / XLSX file
- URL to a CSV / XLSX file
- Pandas DataFrame
model = bc.train(file="data.csv", target="Y_column") #local file
model = bc.train(file="https://example.com/data.csv", target="Y_column") #url
model = bc.train(df=my_df, target="Y_column") #DataFrame
Pre-processing
The framework has built-in support for several data pre-processing techniques, such as imputing missing values, column encoding, and data scaling.
Pre-processing is carried out automatically on train data. The predict function carries out the same pre-processing on new data. The user is not required to be concerned with the pre-processing choices of the framework.
One can view the pre-processing methods used on the data by exporting the entire model configuration to a YAML file. Check the section below on "Exporting to YAML."
Feature Selection
model.features() #prints the features selected by the model
['Present_Price',
'Vehicle_Age',
'Fuel_Type_CNG',
'Fuel_Type_Diesel',
'Fuel_Type_Petrol',
'Seller_Type_Dealer',
'Seller_Type_Individual',
'Transmission_Automatic',
'Transmission_Manual']
AutoAI automatically performs a feature selection on input data. All features (except target) are potential candidates for the X input.
AutoAI will automatically remove ID / Primary-key columns.
This does not guarantee that all specified features will be used in the final model. The framework will perform an automated feature selection from amongst these features. This only guarantees that other features if present in the data will not be considered.
AutoAI ignores features that have a low importance to the effective output. The feature importance plot can be viewed.
model.plot_feature_importance() #shows a feature importance graph
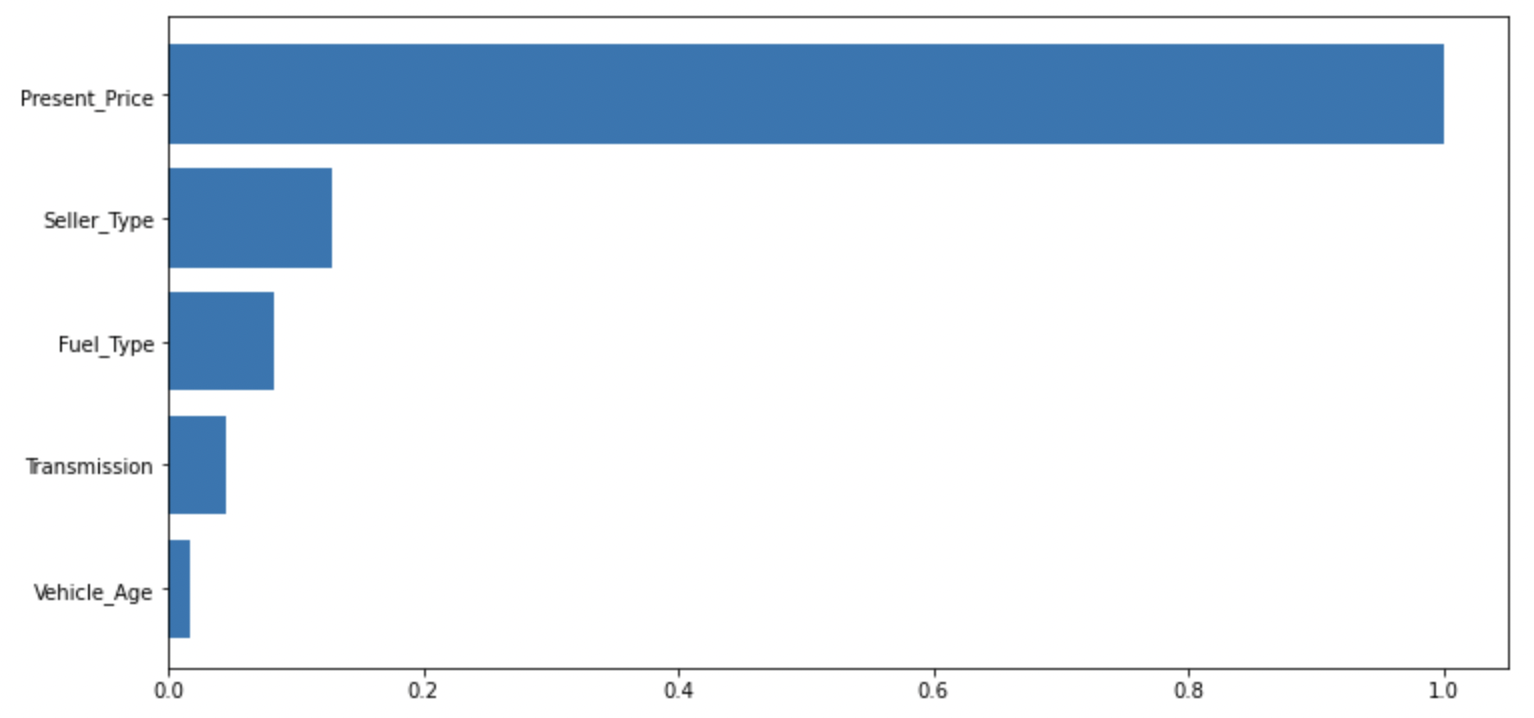
There might be scenarios where you want to explicitely exclude some columns, or only use a subset of columns in the training. Manually specify the features to be used. AutoAI will still perform a feature selection within the list of features provided to improve effective model accuracy.
model = bc.train(file="data.csv", target="Y_value", features=["col1", "col2", "col3"])
Model Search, Train & Hyper-parameter Tuning
Model search, train and hyper-parameter tuning is fully automatic. It is a 3 step process that tests your data across various AI/ML models. It finds models with high success tendency, and performs a hyper-parameter tuning to find you the best possible result.
Code Generation
High-quality code generation is why most Data Scientists choose AutoAI. The spill function generates the model code with exhaustive documentation. scikit-learn models export with training code included. TensorFlow and other DNN models produce only the test / final use code.
Code generation is supported in ipynb and py file formats, with options to enable or disable detailed documentation exports.
model.spill("my_code.ipynb"); #produces Jupyter Notebook file with full markdown docs
model.spill("my_code.py") #produces python code with minimal docs
model.spill("my_code.py", docs=True) #python code with full docs
model.spill("my_code.ipynb", docs=False) #Notebook file with minimal markdown
Predictions
Use a trained model to generate predictions on new data.
prediction = model.predict(file="unseen_data.csv")
All required features must be present in the unseen_data.csv file. Consider checking the results of the automatic feature selection to know the list of features needed by the predict function.
Stats & Accuracy
model.plot_prediction()
The function is shared across Regression and Classification problems. It plots a relevant chart to assess efficiency of training.
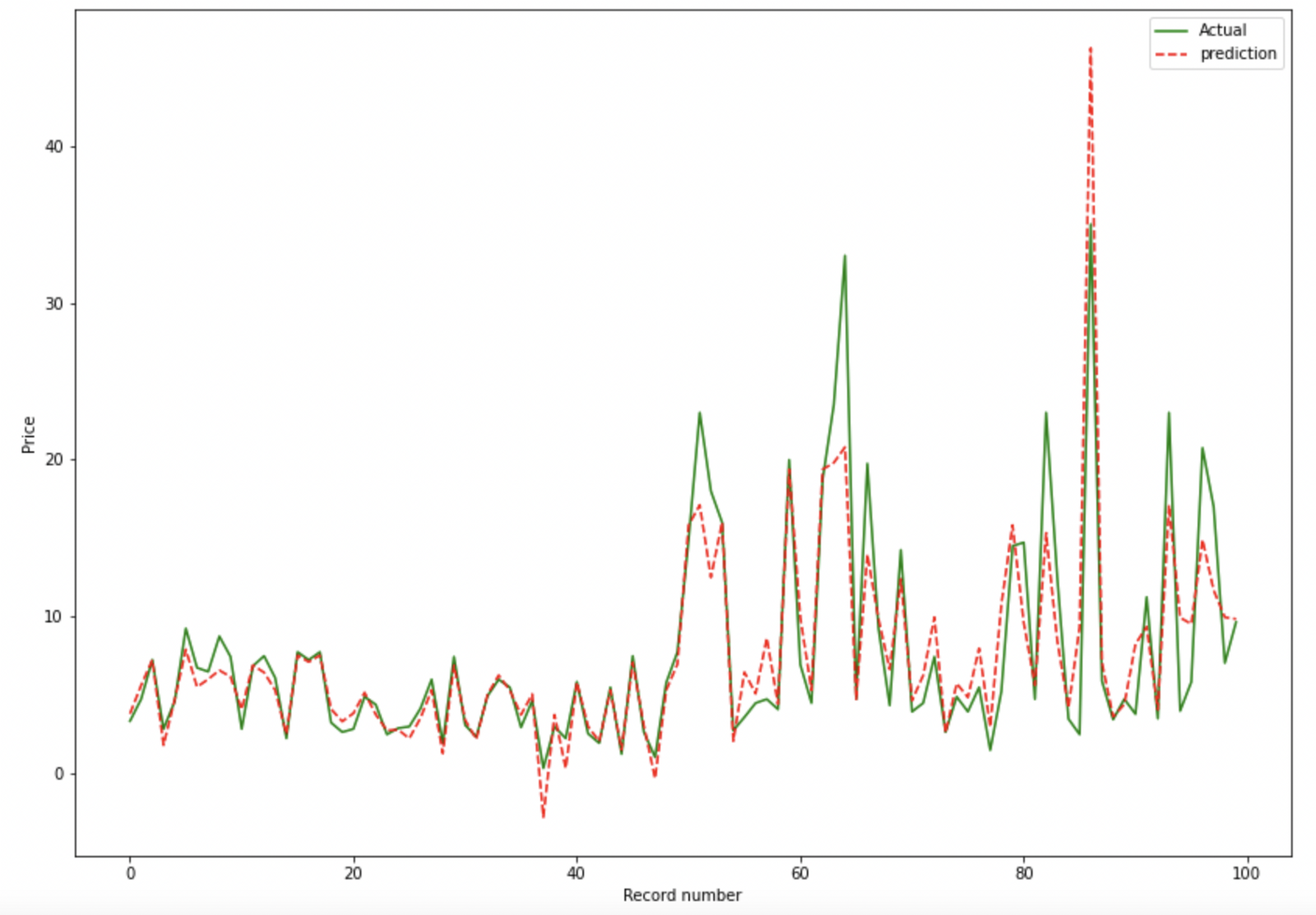
Actual v/s Predicted Plot (for Regression)
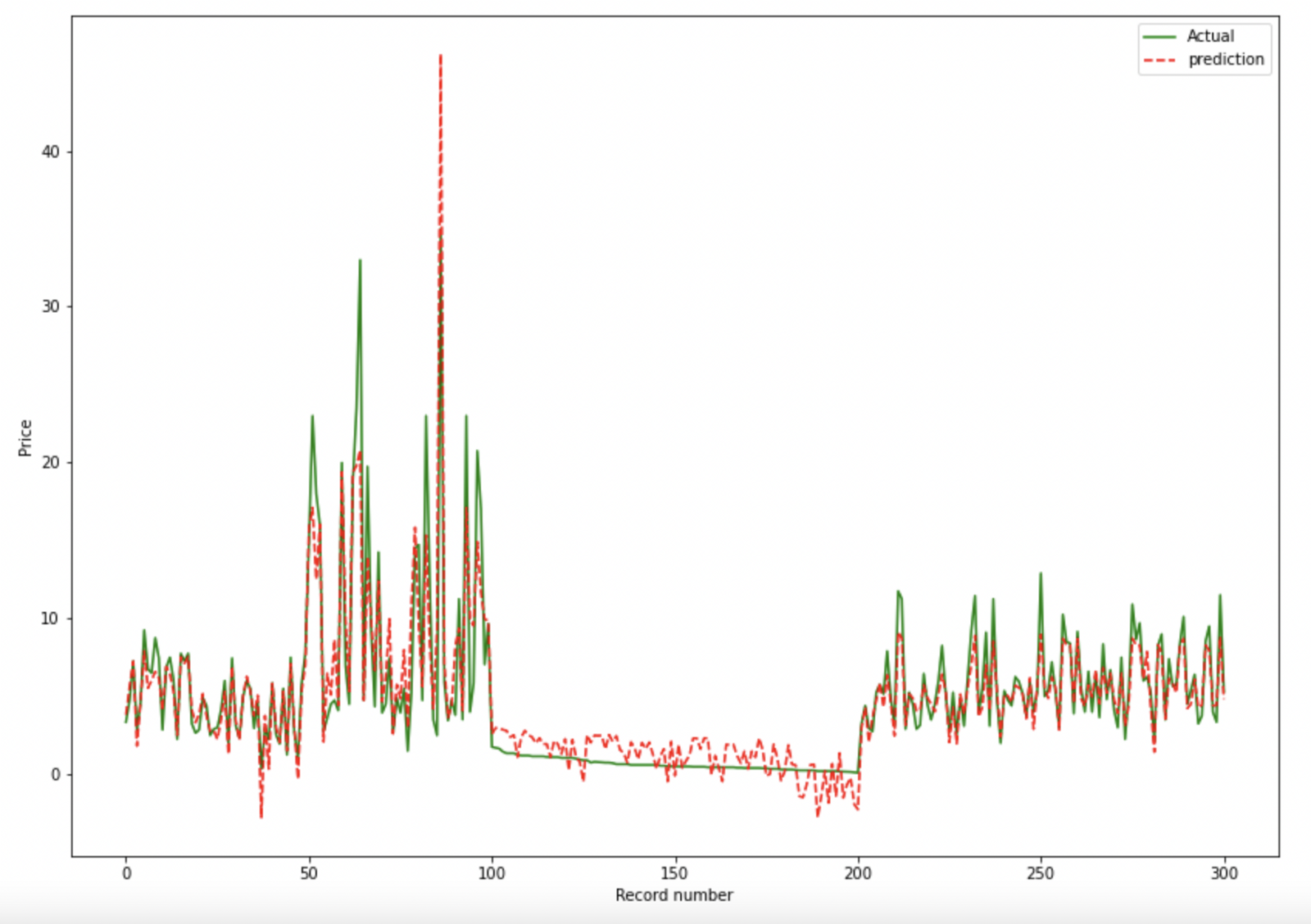
Plotting only first 100 rows. You can specify -100 to plot last 100 rows.
model.plot_prediction(100)
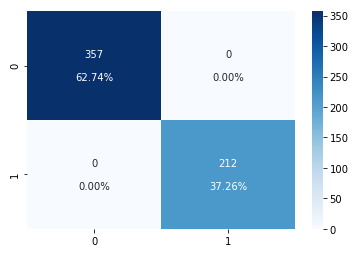
Confusion Matrix (for Classification)
model.plot_prediction()
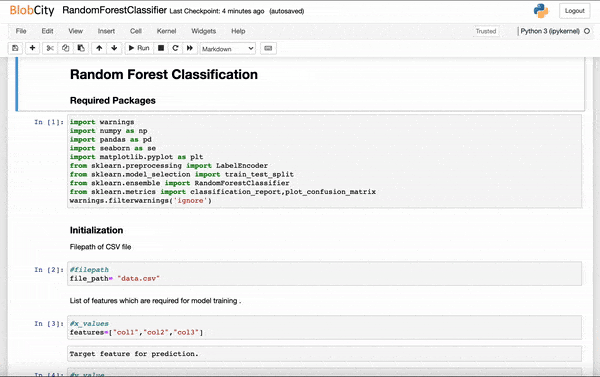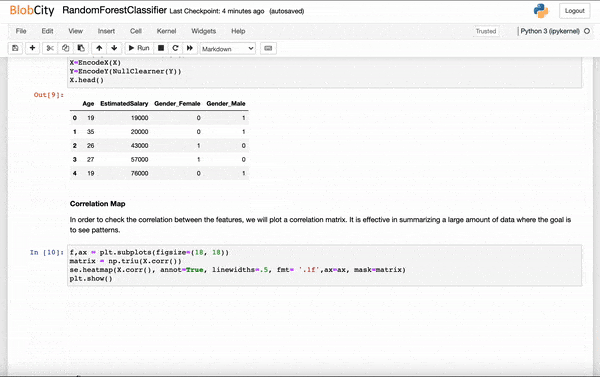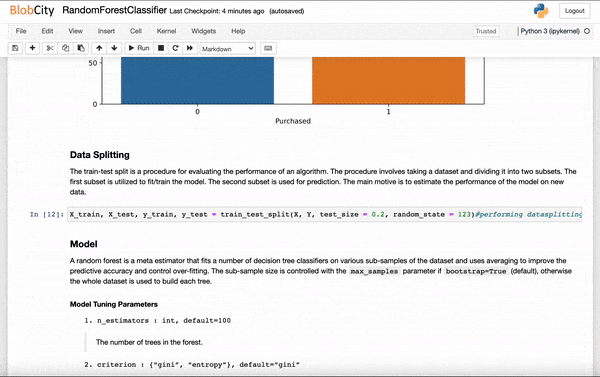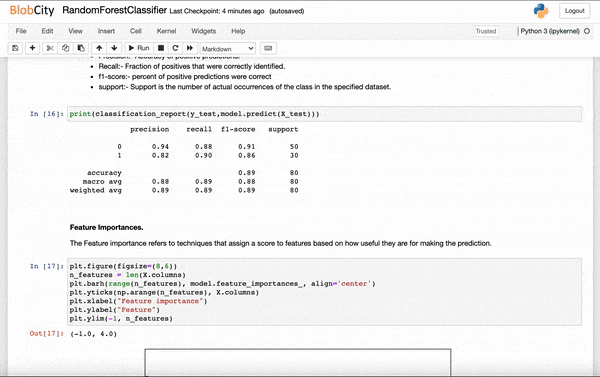
Numercial Stats
model.stats()
Print the key model parameters, such as Precision, Recall, F1-Score. The parameters change based on the type of AutoAI problem.
Persistence
model.save('./my_model.pkl')
model = bc.load('./my_model.pkl')
You can save a trained model, and load it in the future to generate predictions.
Accelerated Training
Leverage BlobCity AI Cloud for fast training on large datasets. Reasonable cloud infrastructure included for free.
Features and Roadmap
- Numercial data Classification and Regression
- Automatic feature selection
- Code generation
- Neural Networks & Deep Learning
- Image classification
- Optical Character Recognition (english only)
- Video tagging with YOLO
- Generative AI using GAN








 148 Dec 28, 2022
148 Dec 28, 2022
 81 Dec 09, 2022
81 Dec 09, 2022
 709 Jan 03, 2023
709 Jan 03, 2023
 115 Dec 17, 2022
115 Dec 17, 2022
 2 Mar 04, 2022
2 Mar 04, 2022
 43 Nov 07, 2022
43 Nov 07, 2022
 16 Dec 15, 2022
16 Dec 15, 2022
 3 Oct 03, 2022
3 Oct 03, 2022
 24 Oct 16, 2022
24 Oct 16, 2022
 11 Oct 29, 2022
11 Oct 29, 2022
 6 May 24, 2021
6 May 24, 2021
 4k Jan 08, 2023
4k Jan 08, 2023
 16 Nov 14, 2022
16 Nov 14, 2022
 75 Dec 22, 2022
75 Dec 22, 2022
 1 Jan 31, 2022
1 Jan 31, 2022
 46 Nov 30, 2022
46 Nov 30, 2022
 75 Dec 13, 2022
75 Dec 13, 2022
 48 Nov 27, 2022
48 Nov 27, 2022
 1.7k Dec 30, 2022
1.7k Dec 30, 2022
 2 Sep 15, 2022
2 Sep 15, 2022