MEAL-V2
This is the official pytorch implementation of our paper: "MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks" by Zhiqiang Shen and Marios Savvides from Carnegie Mellon University.
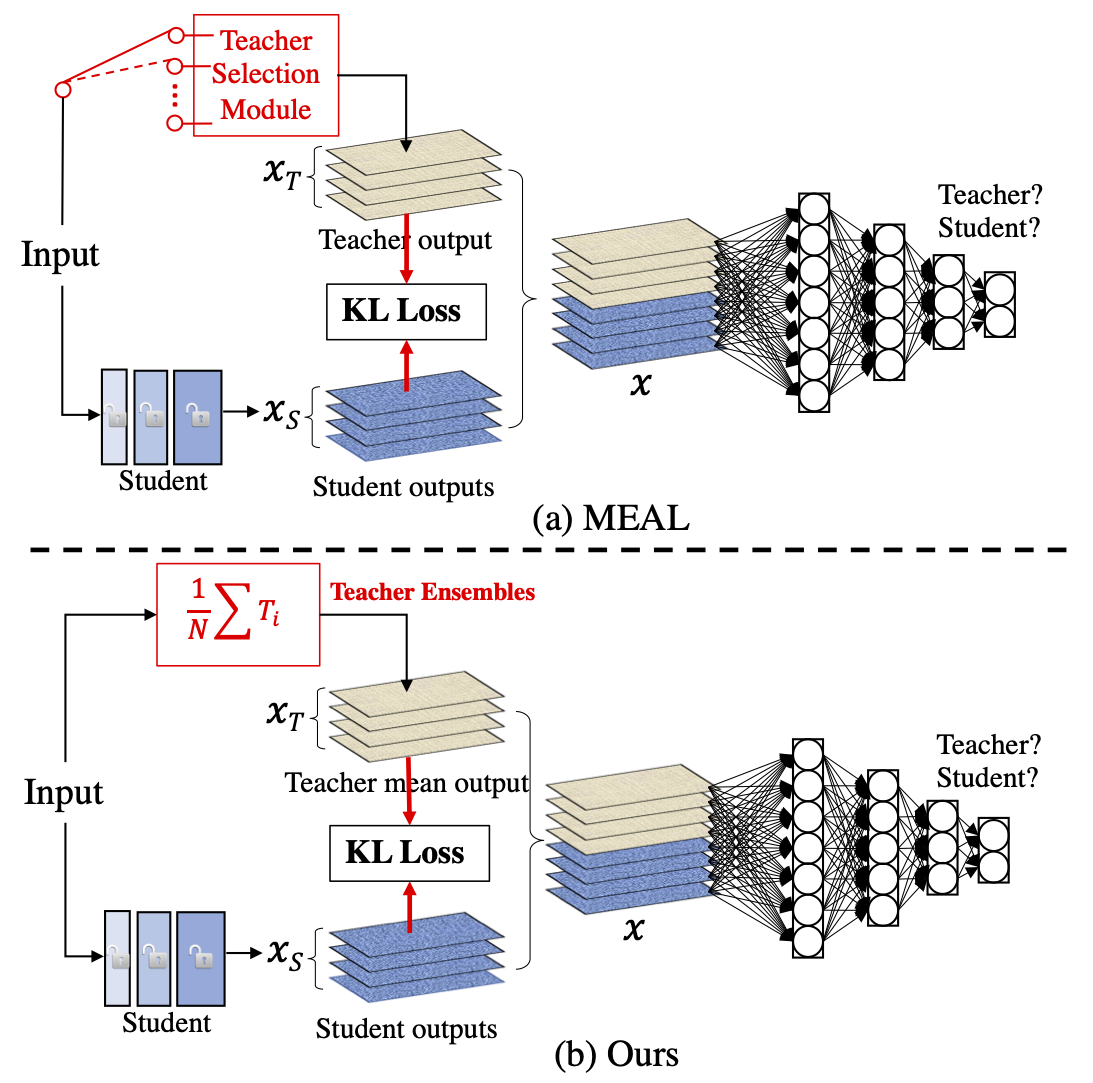
In this paper, we introduce a simple yet effective approach that can boost the vanilla ResNet-50 to 80%+ Top-1 accuracy on ImageNet without any tricks. Generally, our method is based on the recently proposed MEAL, i.e., ensemble knowledge distillation via discriminators. We further simplify it through 1) adopting the similarity loss and discriminator only on the final outputs and 2) using the average of softmax probabilities from all teacher ensembles as the stronger supervision for distillation. One crucial perspective of our method is that the one-hot/hard label should not be used in the distillation process. We show that such a simple framework can achieve state-of-the-art results without involving any commonly-used tricks, such as 1) architecture modification; 2) outside training data beyond ImageNet; 3) autoaug/randaug; 4) cosine learning rate; 5) mixup/cutmix training; 6) label smoothing; etc.
Citation
If you find our code is helpful for your research, please cite:
@article{shen2020mealv2,
title={MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks},
author={Shen, Zhiqiang and Savvides, Marios},
journal={arXiv preprint arXiv:2009.08453},
year={2020}
}
News
[Dec. 5, 2021] New: Add FKD training support. We highly recommend to use FKD for training MEAL V2 models, which will be 2~4x faster with similar accuracy.
-
Download our soft label for MEAL V2.
-
run
FKD_train.pywith the desired model architecture, the path to the ImageNet dataset and the path to the soft label, for example:# 224 x 224 ResNet-50 python FKD_train.py --save MEAL_V2_resnet50_224 \ --batch-size 512 -j 48 \ --model resnet50 --epochs 180 \ --teacher-model gluon_senet154,gluon_resnet152_v1s \ --imagenet [imagenet-folder with train and val folders] \ --num_crops 8 --soft_label_type marginal_smoothing_k5 \ --softlabel_path [path of soft label] \ --schedule 100 180 --use-discriminator-loss
Add --cos if you would like to train with cosine learning rate.
New: Basically, adding back tricks (cosine lr, etc.) into MEAL V2 can consistently improve the accuracy:


New: Add CutMix training support, use --w-cutmix to enable it.
[Mar. 19, 2021] Long version of MEAL V2 is available on: arXiv or paper.
[Dec. 16, 2020] MEAL V2 is now available in PyTorch Hub.
[Nov. 3, 2020] Short version of MEAL V2 has been accepted in NeurIPS 2020 Beyond BackPropagation: Novel Ideas for Training Neural Architectures workshop. Long version is coming soon.
Preparation
1. Requirements:
This repo is tested with:
-
Python 3.6
-
CUDA 10.2
-
PyTorch 1.6.0
-
torchvision 0.7.0
-
timm 0.2.1 (pip install timm)
But it should be runnable with other PyTorch versions.
2. Data:
- Download ImageNet dataset following https://github.com/pytorch/examples/tree/master/imagenet#requirements.
Results & Models
We provide pre-trained models with different trainings, we report in the table training/validation resolution, #parameters, Top-1 and Top-5 accuracy on ImageNet validation set:
| Models | Resolution | #Parameters | Top-1/Top-5 | Trained models |
|---|---|---|---|---|
| MEAL-V1 w/ ResNet50 | 224 | 25.6M | 78.21/94.01 | GitHub |
| MEAL-V2 w/ ResNet18 | 224 | 11.7M | 73.19/90.82 | Download (46.8M) |
| MEAL-V2 w/ ResNet50 | 224 | 25.6M | 80.67/95.09 | Download (102.6M) |
| MEAL-V2 w/ ResNet50 | 380 | 25.6M | 81.72/95.81 | Download (102.6M) |
| MEAL-V2 + CutMix w/ ResNet50 | 224 | 25.6M | 80.98/95.35 | Download (102.6M) |
| MEAL-V2 w/ MobileNet V3-Small 0.75 | 224 | 2.04M | 67.60/87.23 | Download (8.3M) |
| MEAL-V2 w/ MobileNet V3-Small 1.0 | 224 | 2.54M | 69.65/88.71 | Download (10.3M) |
| MEAL-V2 w/ MobileNet V3-Large 1.0 | 224 | 5.48M | 76.92/93.32 | Download (22.1M) |
| MEAL-V2 w/ EfficientNet-B0 | 224 | 5.29M | 78.29/93.95 | Download (21.5M) |
Training & Testing
1. Training:
-
To train a model, run script/train.sh with the desired model architecture and the path to the ImageNet dataset, for example:
# 224 x 224 ResNet-50 python train.py --save MEAL_V2_resnet50_224 --batch-size 512 -j 48 --model resnet50 --epochs 180 --teacher-model gluon_senet154,gluon_resnet152_v1s --imagenet [imagenet-folder with train and val folders]# 224 x 224 ResNet-50 w/ CutMix python train.py --save MEAL_V2_resnet50_224 --batch-size 512 -j 48 --model resnet50 --epochs 180 --teacher-model gluon_senet154,gluon_resnet152_v1s --imagenet [imagenet-folder with train and val folders] --w-cutmix# 380 x 380 ResNet-50 python train.py --save MEAL_V2_resnet50_380 --batch-size 512 -j 48 --model resnet50 --image-size 380 --teacher-model tf_efficientnet_b4_ns,tf_efficientnet_b4 --imagenet [imagenet-folder with train and val folders]# 224 x 224 MobileNet V3-Small 0.75 python train.py --save MEAL_V2_mobilenetv3_small_075 --batch-size 512 -j 48 --model tf_mobilenetv3_small_075 --teacher-model gluon_senet154,gluon_resnet152_v1s --imagenet [imagenet-folder with train and val folders]# 224 x 224 MobileNet V3-Small 1.0 python train.py --save MEAL_V2_mobilenetv3_small_100 --batch-size 512 -j 48 --model tf_mobilenetv3_small_100 --teacher-model gluon_senet154,gluon_resnet152_v1s --imagenet [imagenet-folder with train and val folders]# 224 x 224 MobileNet V3-Large 1.0 python train.py --save MEAL_V2_mobilenetv3_large_100 --batch-size 512 -j 48 --model tf_mobilenetv3_large_100 --teacher-model gluon_senet154,gluon_resnet152_v1s --imagenet [imagenet-folder with train and val folders]# 224 x 224 EfficientNet-B0 python train.py --save MEAL_V2_efficientnet_b0 --batch-size 512 -j 48 --model tf_efficientnet_b0 --teacher-model gluon_senet154,gluon_resnet152_v1s --imagenet [imagenet-folder with train and val folders]
Please reduce the --batch-size if you get ''out of memory'' error. We also notice that more training epochs can slightly improve the performance.
-
To resume training a model, run script/resume_train.sh with the desired model architecture, starting number of training epoch and the path to the ImageNet dataset:
sh script/resume_train.sh
2. Testing:
-
To test a model, run inference.py with the desired model architecture, model path, resolution and the path to the ImageNet dataset:
CUDA_VISIBLE_DEVICES=0,1,2,3 python inference.py -a resnet50 --res 224 --resume MODEL_PATH -e [imagenet-folder with train and val folders]
change --res with other image resolution [224/380] and -a with other model architecture [tf_mobilenetv3_small_100; tf_mobilenetv3_large_100; tf_efficientnet_b0] to test other trained models.
Contact
Zhiqiang Shen, CMU (zhiqians at andrew.cmu.edu)
Any comments or suggestions are welcome!















 30 Jan 01, 2023
30 Jan 01, 2023
 10 Nov 30, 2022
10 Nov 30, 2022
 11 Jul 24, 2022
11 Jul 24, 2022
 80 Dec 27, 2022
80 Dec 27, 2022
 55 Nov 23, 2022
55 Nov 23, 2022
 28 Aug 25, 2022
28 Aug 25, 2022
 117 Dec 27, 2022
117 Dec 27, 2022
 4 Feb 22, 2022
4 Feb 22, 2022
 303 Dec 31, 2022
303 Dec 31, 2022
 10 Oct 11, 2022
10 Oct 11, 2022
 431 Jan 03, 2023
431 Jan 03, 2023
 2.8k Jan 08, 2023
2.8k Jan 08, 2023
 0 Jan 06, 2022
0 Jan 06, 2022
 489 Jan 07, 2023
489 Jan 07, 2023
 13 Jan 04, 2023
13 Jan 04, 2023
 28 Nov 25, 2022
28 Nov 25, 2022
 28 Sep 16, 2022
28 Sep 16, 2022
 7k Dec 30, 2022
7k Dec 30, 2022
 80 Dec 05, 2022
80 Dec 05, 2022
 8 Nov 24, 2022
8 Nov 24, 2022