PizzaOrders_DataPipeline
There is a Tony who is owning a New Pizza shop.
He knew that pizza alone was not going to help him get seed funding to expand his new Pizza Empire
so he had one more genius idea to combine with it - he was going to Uberize it - and so Pizza Runner was launched!
Tony started by recruiting “runners” to deliver fresh pizza from Pizza Runner Headquarters (otherwise known as Tony’s house) and also maxed out his credit card to pay freelance developers to build a mobile app to accept orders from customers.
Now he wants to know how is his business going on he needs some answers to his questions from the data. but the data which is stored is not in an appropriate format. He Approaches a Data Engineer to process and store the data for him and get the answers to his question
The data are stored in the different CSV files
- customer_orders.csv
Columns=>order_id,customer_id,pizza_id,exclusions,extras,order_time - pizza_names.csv
Columns=> pizza_id,pizza_name - pizza_recipes.csv
Columns=>pizza_id,toppings - pizza_toppings.csv
Columns=>topping_id,topping_name - runner_orders.csv
Columns=>order_id,runner_id,pickup_time,distance,duration,cancellation
- runners.csv
Columns=> runner_id,registration_date
The Answers the Tony wanted for
- How many pizzas were ordered?
- How many unique customer orders were made?
- How many successful orders were delivered by each runner?
- How many of each type of pizza was delivered?
- How many Vegetarian and Meatlovers were ordered by each customer?
- What was the maximum number of pizzas delivered in a single order?
- For each customer, how many delivered pizzas had at least 1 change and how many had no changes?
- How many pizzas were delivered that had both exclusions and extras?
- What was the total volume of pizzas ordered for each hour of the day?
- Wh/at was the volume of orders for each day of the week?
Requirements
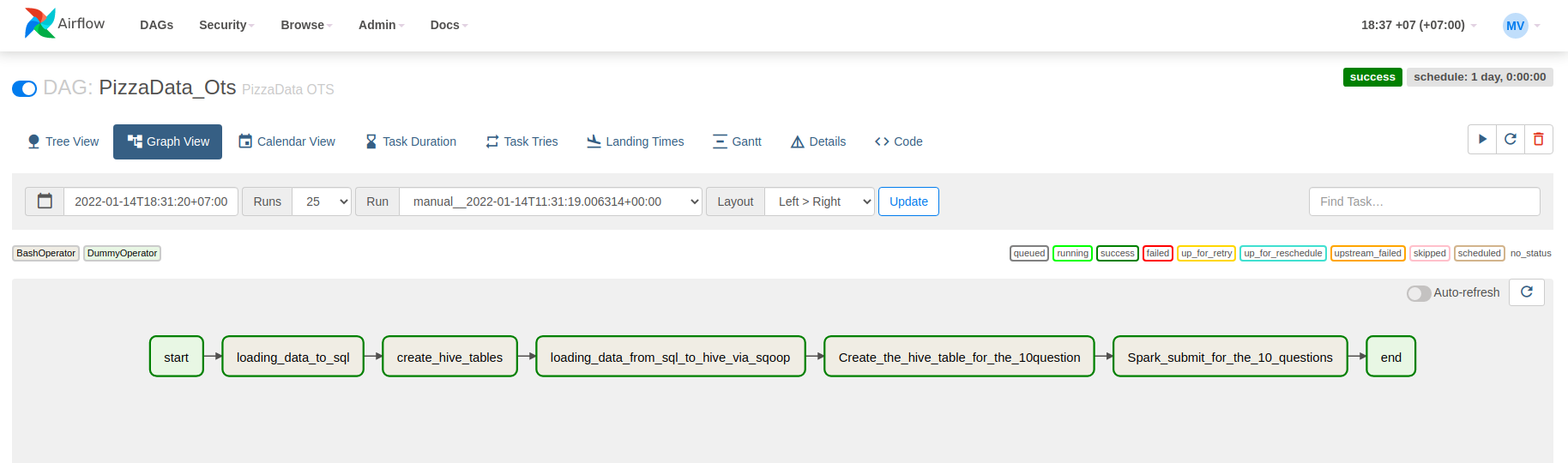
- Store the data In MY SQL table
- Using Sqoop Store the Data in Hive
- Using the PySpark the get the Results for the question
- Store the Results in Seperate Table
- Automate entire process in the Airflow

AirFlow Output


 1 Nov 13, 2021
1 Nov 13, 2021
 1 Nov 02, 2021
1 Nov 02, 2021
 27 Dec 22, 2022
27 Dec 22, 2022
 3 Feb 12, 2022
3 Feb 12, 2022
 67 Dec 27, 2022
67 Dec 27, 2022
 3.6k Jan 09, 2023
3.6k Jan 09, 2023
 1 Nov 17, 2021
1 Nov 17, 2021
 1 Jan 02, 2022
1 Jan 02, 2022
 1.6k Jan 03, 2023
1.6k Jan 03, 2023
 3 Jun 30, 2022
3 Jun 30, 2022
 7 Nov 20, 2022
7 Nov 20, 2022
 3 Nov 08, 2022
3 Nov 08, 2022
 4 Jan 23, 2022
4 Jan 23, 2022
 4 Feb 11, 2022
4 Feb 11, 2022
 5 Dec 22, 2021
5 Dec 22, 2021
 32 Nov 27, 2022
32 Nov 27, 2022
 6 Sep 07, 2022
6 Sep 07, 2022
 38 Nov 16, 2022
38 Nov 16, 2022
 1 Dec 22, 2021
1 Dec 22, 2021
 1 Sep 03, 2022
1 Sep 03, 2022