HiPlot - High dimensional Interactive Plotting 

![]()


HiPlot is a lightweight interactive visualization tool to help AI researchers discover correlations and patterns in high-dimensional data using parallel plots and other graphical ways to represent information.
Try a demo now with sweep data or upload your CSV or 
There are several modes to HiPlot:
- As a web-server (if your data is a CSV for instance)
- In a jupyter notebook (to visualize python data), or in Streamlit apps
- In CLI to render standalone HTML
pip install -U hiplot # Or for conda users: conda install -c conda-forge hiplot
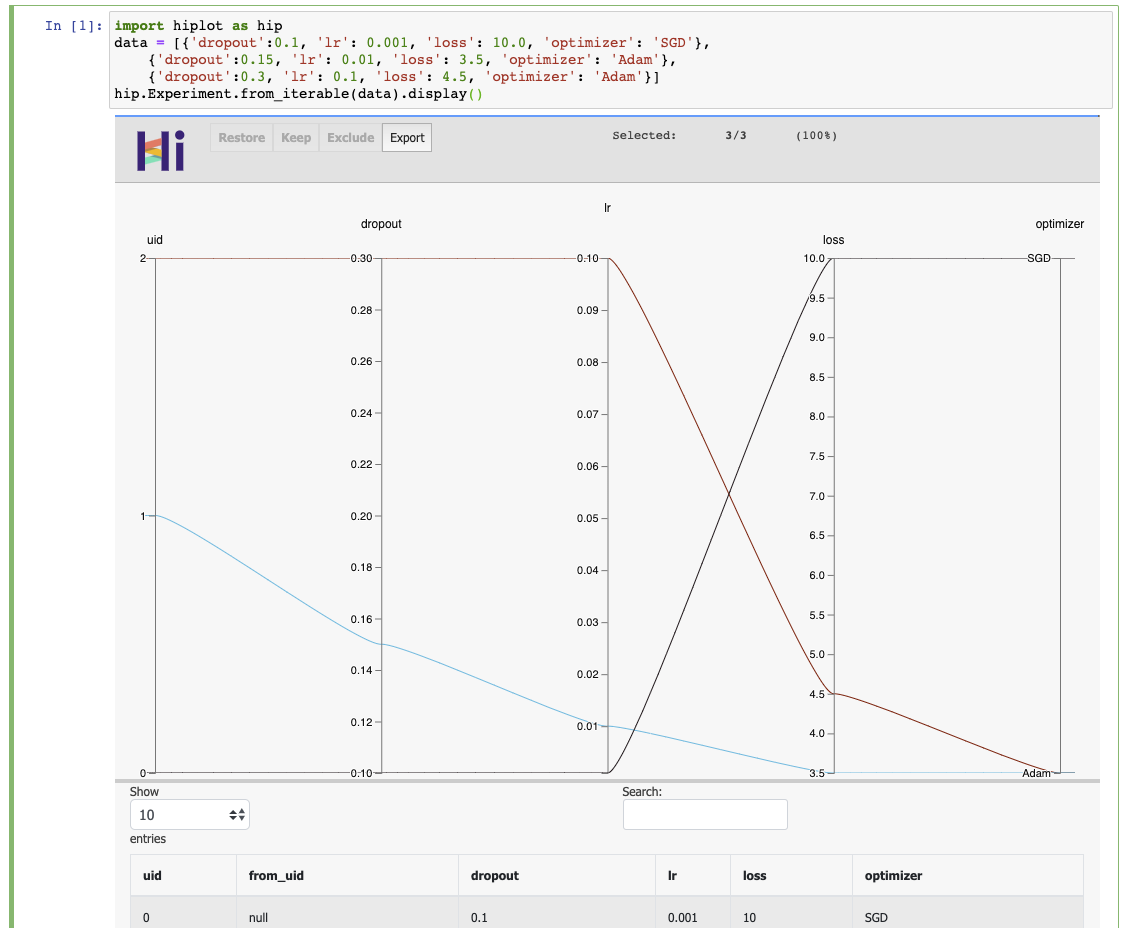
If you have a jupyter notebook, you can get started with something as simple as:
import hiplot as hip
data = [{'dropout':0.1, 'lr': 0.001, 'loss': 10.0, 'optimizer': 'SGD'},
{'dropout':0.15, 'lr': 0.01, 'loss': 3.5, 'optimizer': 'Adam'},
{'dropout':0.3, 'lr': 0.1, 'loss': 4.5, 'optimizer': 'Adam'}]
hip.Experiment.from_iterable(data).display()
See the live result
Links
- Blog post: https://ai.facebook.com/blog/hiplot-high-dimensional-interactive-plots-made-easy/
- Documentation: https://facebookresearch.github.io/hiplot/index.html
- Pypi package: https://pypi.org/project/hiplot/
- Conda package: https://anaconda.org/conda-forge/hiplot
- NPM package: https://www.npmjs.com/package/hiplot
- Examples: https://github.com/facebookresearch/hiplot/tree/master/examples
Citing
@misc{hiplot,
author = {Haziza, D. and Rapin, J. and Synnaeve, G.},
title = {{Hiplot, interactive high-dimensionality plots}},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/facebookresearch/hiplot}},
}
Credits
Inspired by and based on code from Kai Chang, Mike Bostock and Jason Davies.
External contributors (please add your name when you submit your first pull request):



![[Windows] UnicodeDecodeError](https://avatars.githubusercontent.com/u/32923721?v=4)







 turned into
turned into  which cuts off the final column name if I make the window any more narrow and causes a weird spacing issue on the right-side.
which cuts off the final column name if I make the window any more narrow and causes a weird spacing issue on the right-side.



 110 Dec 22, 2022
110 Dec 22, 2022
 8 Dec 14, 2022
8 Dec 14, 2022
 466 Jan 09, 2023
466 Jan 09, 2023
 2 Jun 08, 2022
2 Jun 08, 2022
 1 Feb 10, 2022
1 Feb 10, 2022
 3 Dec 30, 2022
3 Dec 30, 2022
 17 Dec 08, 2022
17 Dec 08, 2022
 11 Dec 01, 2022
11 Dec 01, 2022
 5 Dec 19, 2021
5 Dec 19, 2021
 5 Nov 12, 2022
5 Nov 12, 2022
 41 Dec 10, 2022
41 Dec 10, 2022
 1.8k Jan 07, 2023
1.8k Jan 07, 2023
 697 Jan 06, 2023
697 Jan 06, 2023
 1 Sep 01, 2022
1 Sep 01, 2022
 50 Jul 17, 2022
50 Jul 17, 2022
 3 May 14, 2022
3 May 14, 2022
 16 Jan 03, 2023
16 Jan 03, 2023
 247 Dec 18, 2021
247 Dec 18, 2021
 3.3k Dec 27, 2022
3.3k Dec 27, 2022
 5 Oct 10, 2022
5 Oct 10, 2022