J.A.R.V.I.S
Kindly consider starring this repository if you like the program :-)


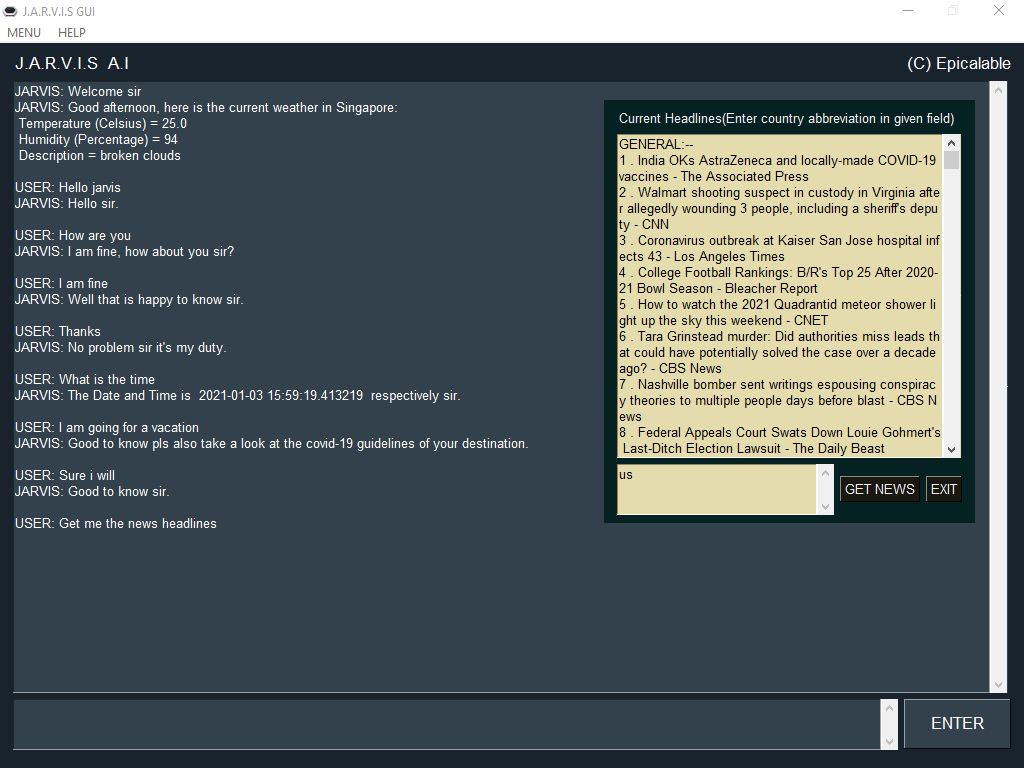
What/Who is J.A.R.V.I.S?
J.A.R.V.I.S is an chatbot written that is built and coded in Python whose aim is to be capable of chatting and retrieving any information and daily news from the internet for it's user.
Backstory of J.A.R.V.I.S
J.A.R.V.I.S was inspired by by Tony Stark's A.I "J.A.R.V.I.S" from the Iron Man movies from Marvel. Paving the way for my dream to create a bot which can help me in automation by keeping me informed, updated and productive.
What python packages are needed to run J.A.R.V.I.S (Requirements)?
In order for J.A.R.V.I.S to work at full capacity a few 3rd party python packages will be required to be installed:
- pip install PySimpleGUI == 4.33.0
- pip install requests == 2.25.1
- pip install beautifulsoup4 == 4.9.3
- pip install wikipedia == 1.4.0
How does J.A.R.V.I.S store info and is it safe?
Yes, Your info will be safe since it will be stored locally on your personal computer. J.A.R.V.I.S stores mainly 2 types of info.
-
Response-Intents: Stored in Jarintents file used by J.A.R.V.I.S to check input with tags and provide the appropriate output.
-
Info-Intents: Stored in the Jarinfo file used by J.A.R.V.I.S to store Api keys, Name and location for data retrieval. You can access these using the settings menu.
All CRITICAL INFO will be STORED IN your PERSONAL COMPUTER and NOT on the INTERNET.
What kind of API should I subscribe to?
When completed installing by default you can chat with J.A.R.V.I.S but not get any information. To activate it you will need to head to:
-
https://newsapi.org/ : For Live News, Morning Briefings and News Headlines.
-
https://openweathermap.org/ : For current Weather information.
Some examples of J.A.R.V.I.S commands
To make JARVIS respond Users will need to enter a Command in the input for which JARVIS will scan for keywords and provide an answer or information.
Here is a sample list of available Commands:
- Hello
- How are you
- Are you fine
- Are you real
- What is the time
- News about [your input]-- Ex. News about Github.
- Get me news headlines-- NOTE: Type in country's abbreviation in input bar in Newsui. EX. Us, Sg, Uk, Au.
- Send an email
- Wikipedia [Query]-- Ex. Wikipedia github.
- Who is [Query] / What is [Query]-- NOTE: JARVIS will get answer from Wikipedia.
- Get me stock price for [Query]-- NOTE: Query of stock should be abbreviations. EX. TSLA, AAPL, MSFT.
- Goodbye jarvis-- NOTE: Command to quit JARVIS.
License 

IMPORTANT NOTE: Any User who are willing to Share or Re-Distribute the above 'Program' are kindly advised to:
-
keep at least ONE "(C) Epicalable" text in the 'program'.
-
a link to this repository from the user's 'Modified program' README file.
It will be helpful for us as users will know it's original source and about our startup.
THANK YOU FOR YOUR COOPERATION :-)




J.A.R.V.I.S Copyright (C) 2021 Epicalable LLC. All Rights Reserved.

 26 Dec 25, 2022
26 Dec 25, 2022
 922 Dec 31, 2022
922 Dec 31, 2022
 35 Nov 16, 2022
35 Nov 16, 2022
 1 Feb 11, 2022
1 Feb 11, 2022
 8.4k Dec 26, 2022
8.4k Dec 26, 2022
 40 Nov 25, 2022
40 Nov 25, 2022
 52 Jan 05, 2023
52 Jan 05, 2023
 16 Dec 07, 2022
16 Dec 07, 2022
 1.1k Dec 27, 2022
1.1k Dec 27, 2022
 61 Nov 24, 2022
61 Nov 24, 2022
 10 Jul 01, 2022
10 Jul 01, 2022
 7 Jul 18, 2022
7 Jul 18, 2022
 39 Aug 03, 2021
39 Aug 03, 2021
 86 Nov 28, 2022
86 Nov 28, 2022
 24 Dec 29, 2022
24 Dec 29, 2022
 1 Dec 26, 2021
1 Dec 26, 2021
 48 Oct 11, 2022
48 Oct 11, 2022
 2 Feb 17, 2022
2 Feb 17, 2022
 1 Dec 03, 2021
1 Dec 03, 2021