Project A: WebScraper
A script that prints out a list of all EXTERNAL references in the HTML response to an HTTP/S request.
Installing all dependencies
pip install -r requirements.txt or pip3 install -r requirements.txt
Executing the script
python3 external_link.py [URL] \ URL be http://www.abc.com or https://www.abc.com
Example of code USAGE
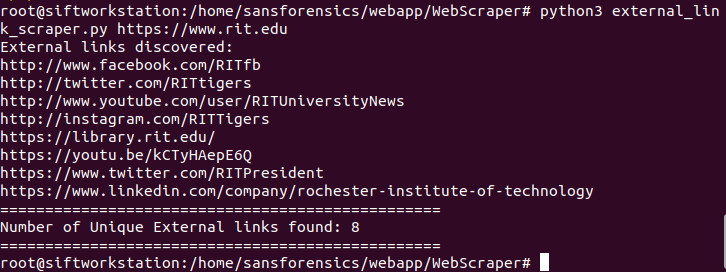
python3 external_link_scraper.py https://www.rit.edu

 150 Oct 15, 2022
150 Oct 15, 2022
 1 Feb 10, 2022
1 Feb 10, 2022
 0 Jan 06, 2022
0 Jan 06, 2022
 18 Dec 31, 2022
18 Dec 31, 2022
 5 Nov 29, 2022
5 Nov 29, 2022
 2 Apr 29, 2022
2 Apr 29, 2022
 3 Oct 04, 2022
3 Oct 04, 2022
 5 Nov 29, 2021
5 Nov 29, 2021
 0 Jan 07, 2022
0 Jan 07, 2022
 1 Nov 03, 2021
1 Nov 03, 2021
 2 Nov 01, 2021
2 Nov 01, 2021
 2.2k Jan 05, 2023
2.2k Jan 05, 2023
 185 Jul 23, 2022
185 Jul 23, 2022
 1 Jul 09, 2022
1 Jul 09, 2022
 1 Nov 17, 2022
1 Nov 17, 2022
 15 Dec 06, 2022
15 Dec 06, 2022
 2.6k Dec 31, 2022
2.6k Dec 31, 2022
 19 Dec 12, 2022
19 Dec 12, 2022
 14 Dec 09, 2022
14 Dec 09, 2022
 11 Jul 27, 2022
11 Jul 27, 2022