Python-Search-Engine-Scrapy || Python-爬虫-索引/利用爬虫获取谷歌信息**/
Searching info from Google using Python Scrapy /* 利用 PYTHON 爬虫获取天气信息,以及城市信息和资料**/
translation time comparation
+------------+----------+ | Library | Time | +------------+----------+ | polyglot | 3.67 s | +------------+----------+ | fasttext | 6.41 | +------------+----------+ | cld3 | 14 s | +------------+----------+ | langid | 1min 8s | +------------+----------+ | langdetect | 2min 53s | +------------+----------+ | chardet | 4min 36s | +------------+----------+ It would generate warning : 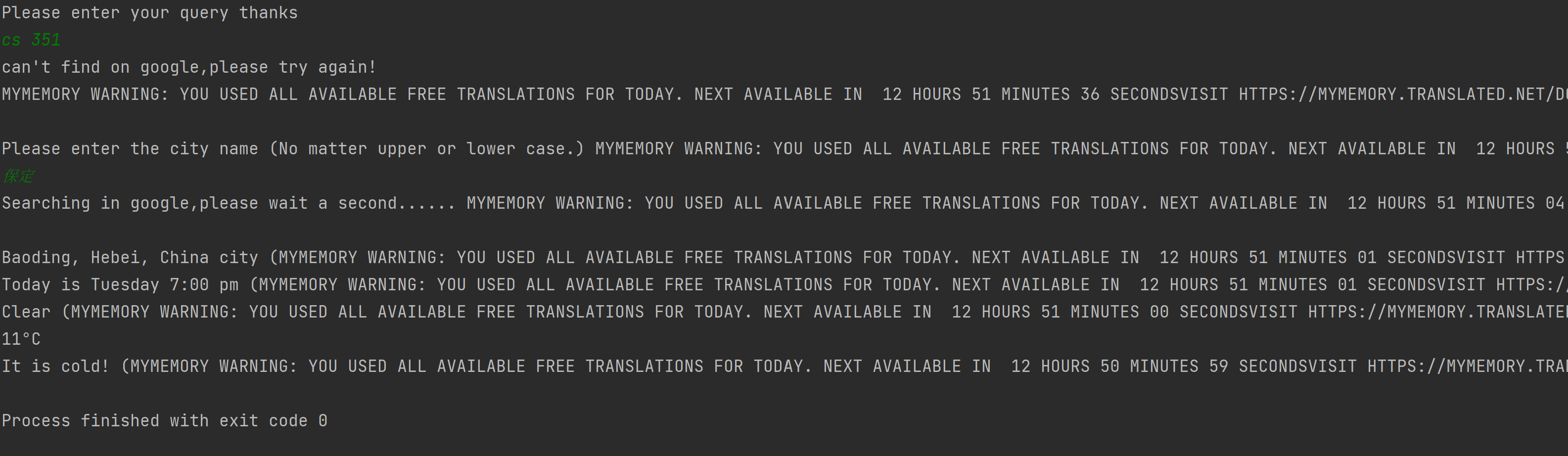



 575 Dec 28, 2022
575 Dec 28, 2022
 16 Sep 17, 2022
16 Sep 17, 2022
 47 Nov 23, 2022
47 Nov 23, 2022
 3 Oct 04, 2022
3 Oct 04, 2022
 3 Apr 15, 2022
3 Apr 15, 2022
 19 Sep 11, 2022
19 Sep 11, 2022
 3 Oct 14, 2022
3 Oct 14, 2022
 1 Dec 07, 2021
1 Dec 07, 2021
 33 Sep 03, 2022
33 Sep 03, 2022
 6 May 02, 2022
6 May 02, 2022
 3 Feb 10, 2022
3 Feb 10, 2022
 3.7k Dec 27, 2022
3.7k Dec 27, 2022
 0 Jan 07, 2022
0 Jan 07, 2022
 2.1k Jan 06, 2023
2.1k Jan 06, 2023
 3 Mar 07, 2022
3 Mar 07, 2022
 590 Jan 03, 2023
590 Jan 03, 2023
 4 Apr 23, 2022
4 Apr 23, 2022
 11 Nov 13, 2022
11 Nov 13, 2022
 15 Sep 01, 2022
15 Sep 01, 2022
 56 Nov 27, 2022
56 Nov 27, 2022