![]()
Ruia




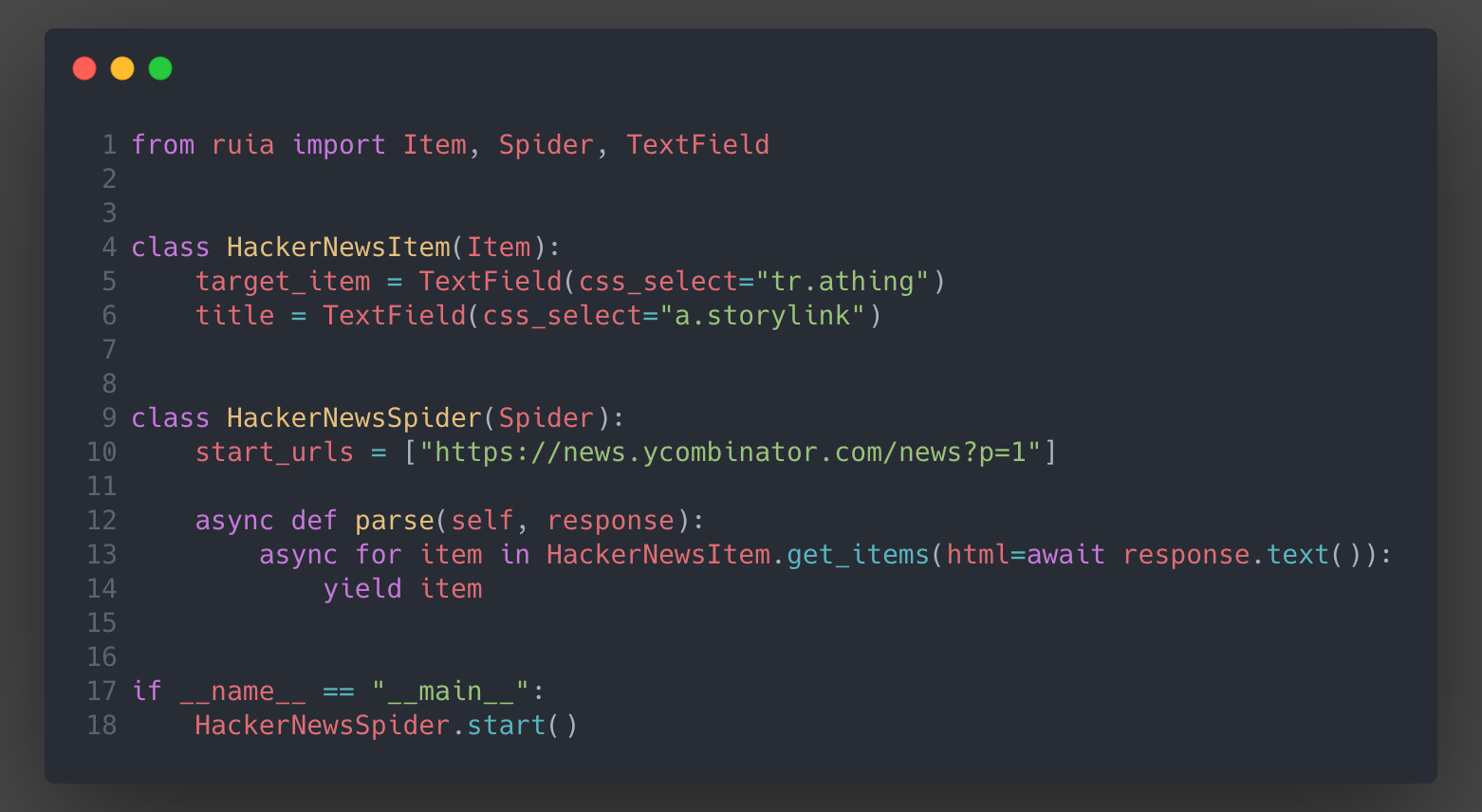
Overview
Ruia is an async web scraping micro-framework, written with asyncio and aiohttp, aims to make crawling url as convenient as possible.
Write less, run faster:
- Documentation: 中文文档 |documentation
- Organization: python-ruia
- Plugin: awesome-ruia(Any contributions you make are greatly appreciated!)
Features
- Easy: Declarative programming
- Fast: Powered by asyncio
- Extensible: Middlewares and plugins
- Powerful: JavaScript support
Installation
# For Linux & Mac
pip install -U ruia[uvloop]
# For Windows
pip install -U ruia
# New features
pip install git+https://github.com/howie6879/ruia
Tutorials
- Overview
- Installation
- Define Data Items
- Spider Control
- Request & Response
- Customize Middleware
- Write a Plugins
TODO
- Cache for debug, to decreasing request limitation, ruia-cache
- Provide an easy way to debug the script, ruia-shell
- Distributed crawling/scraping
Contribution
Ruia is still under developing, feel free to open issues and pull requests:
- Report or fix bugs
- Require or publish plugins
- Write or fix documentation
- Add test cases
!!!Notice: We use black to format the code








 36 Oct 27, 2022
36 Oct 27, 2022
 30 Mar 01, 2022
30 Mar 01, 2022
 11 May 06, 2022
11 May 06, 2022
 3 Feb 13, 2022
3 Feb 13, 2022
 10 Aug 07, 2022
10 Aug 07, 2022
 2 Mar 12, 2022
2 Mar 12, 2022
 14 Aug 12, 2022
14 Aug 12, 2022
 3 Nov 24, 2022
3 Nov 24, 2022
 725 Jan 03, 2023
725 Jan 03, 2023
 13 Dec 27, 2022
13 Dec 27, 2022
 2 May 09, 2022
2 May 09, 2022
 704 Jan 06, 2023
704 Jan 06, 2023
 4 Dec 03, 2022
4 Dec 03, 2022
 11 Nov 13, 2022
11 Nov 13, 2022
 47 Nov 09, 2022
47 Nov 09, 2022
 16 Dec 26, 2022
16 Dec 26, 2022
 3 Jan 03, 2022
3 Jan 03, 2022
 7 Dec 03, 2022
7 Dec 03, 2022
 0 May 15, 2022
0 May 15, 2022
 5 Dec 01, 2022
5 Dec 01, 2022