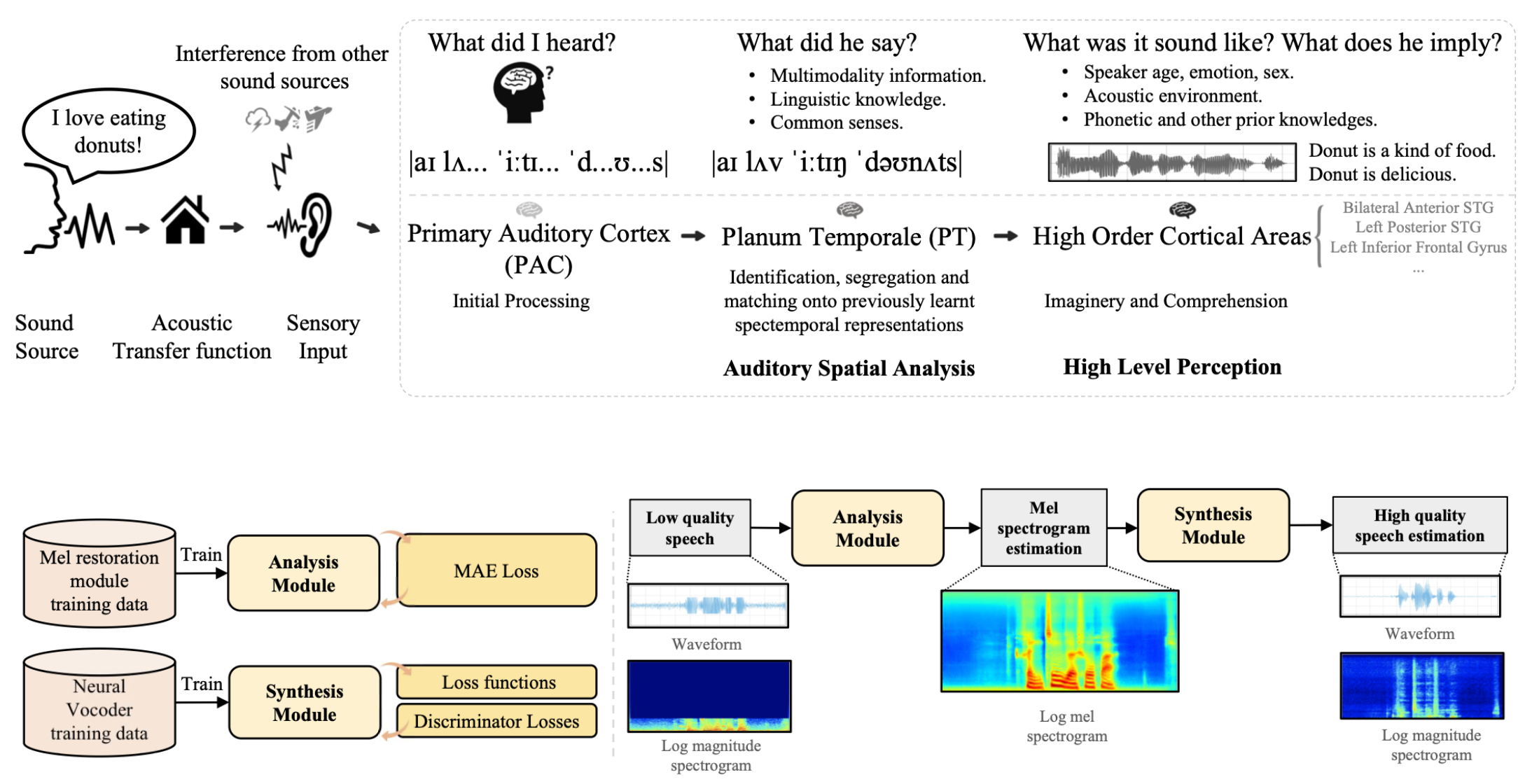
VoiceFixer
Voicefixer aims at the restoration of human speech regardless how serious its degraded. It can handle noise, reveberation, low resolution (2kHz~44.1kHz) and clipping (0.1-1.0 threshold) effect within one model.
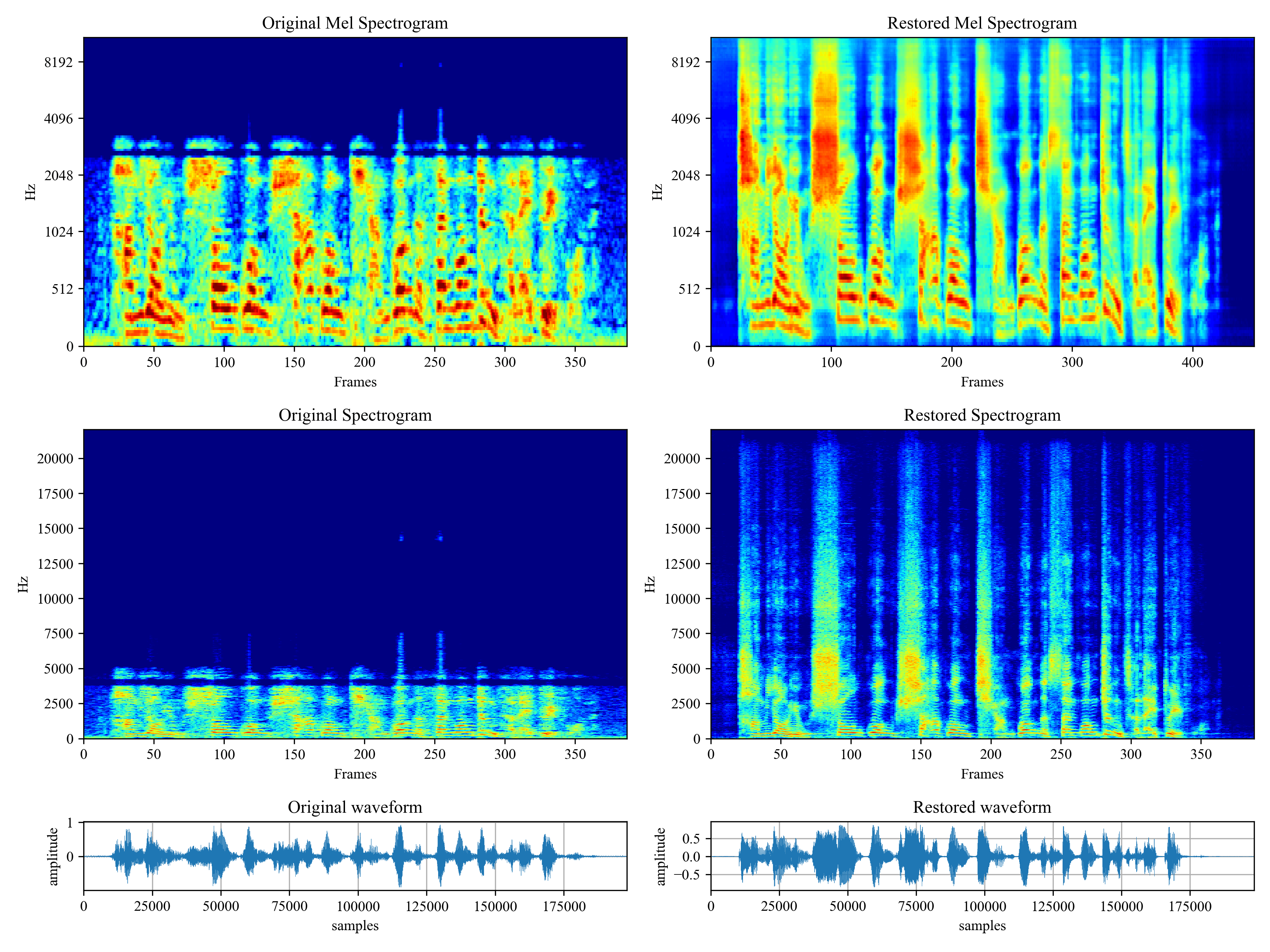
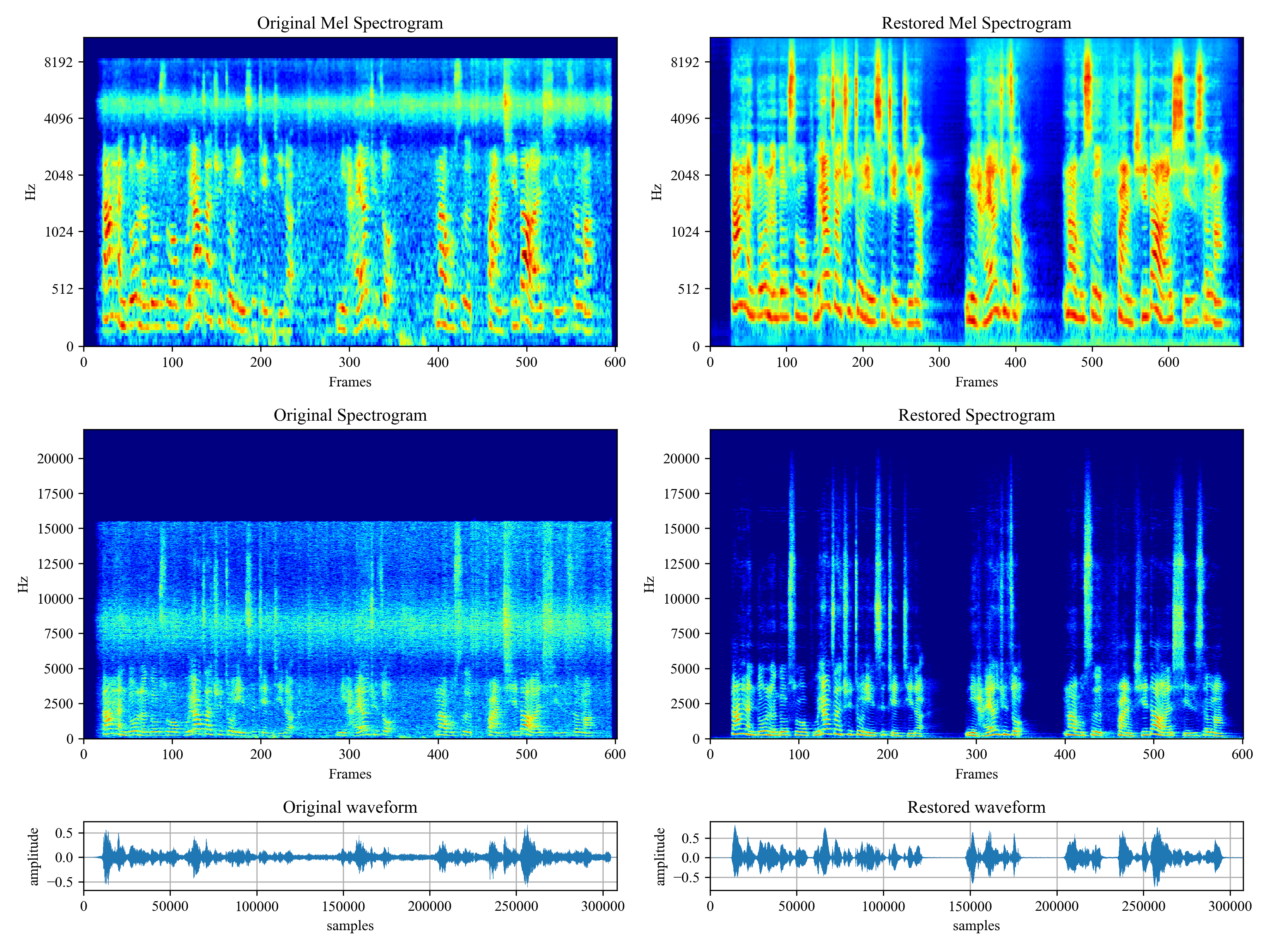
Demo
Please visit demo page to view what voicefixer can do.
Usage
from voicefixer import VoiceFixer
voicefixer = VoiceFixer()
voicefixer.restore(input="", # input wav file path
output="", # output wav file path
cuda=False, # whether to use gpu acceleration
mode = 0) # You can try out mode 0, 1 to find out the best result
from voicefixer import Vocoder
# Universal Speaker Independent Vocoder
vocoder = Vocoder(sample_rate=44100) # only support 44100 sample rate
vocoder.oracle(fpath="", # input wav file path
out_path="") # output wav file path
Related Material
- Paper: Will be available before Oct.03.2021.
- Train & Evaluation pipline (Still working on it): https://github.com/haoheliu/voicefixer_main






 Hi!
Hi!











 7 Jan 21, 2022
7 Jan 21, 2022
 21 Jul 23, 2022
21 Jul 23, 2022
 1 Nov 04, 2021
1 Nov 04, 2021
 1k Jan 09, 2023
1k Jan 09, 2023
 867 Dec 29, 2022
867 Dec 29, 2022
 4 Sep 02, 2022
4 Sep 02, 2022
 3 Jan 08, 2022
3 Jan 08, 2022
 1.2k Jan 07, 2023
1.2k Jan 07, 2023
 1 Jan 10, 2022
1 Jan 10, 2022
 197 Dec 31, 2022
197 Dec 31, 2022
 224 Dec 04, 2022
224 Dec 04, 2022
 25 Nov 08, 2022
25 Nov 08, 2022
 6 Feb 06, 2022
6 Feb 06, 2022
 121 Nov 27, 2022
121 Nov 27, 2022
 124 Dec 22, 2022
124 Dec 22, 2022
 1 Nov 06, 2021
1 Nov 06, 2021
 4 Feb 28, 2022
4 Feb 28, 2022
 0 Jul 03, 2022
0 Jul 03, 2022
 269 Dec 18, 2022
269 Dec 18, 2022
 425 Jan 01, 2023
425 Jan 01, 2023