Scrappp
A Very simple free proxy list scraper, made in python The tool scrape proxy from diffrent sites and api's.
Screenshots
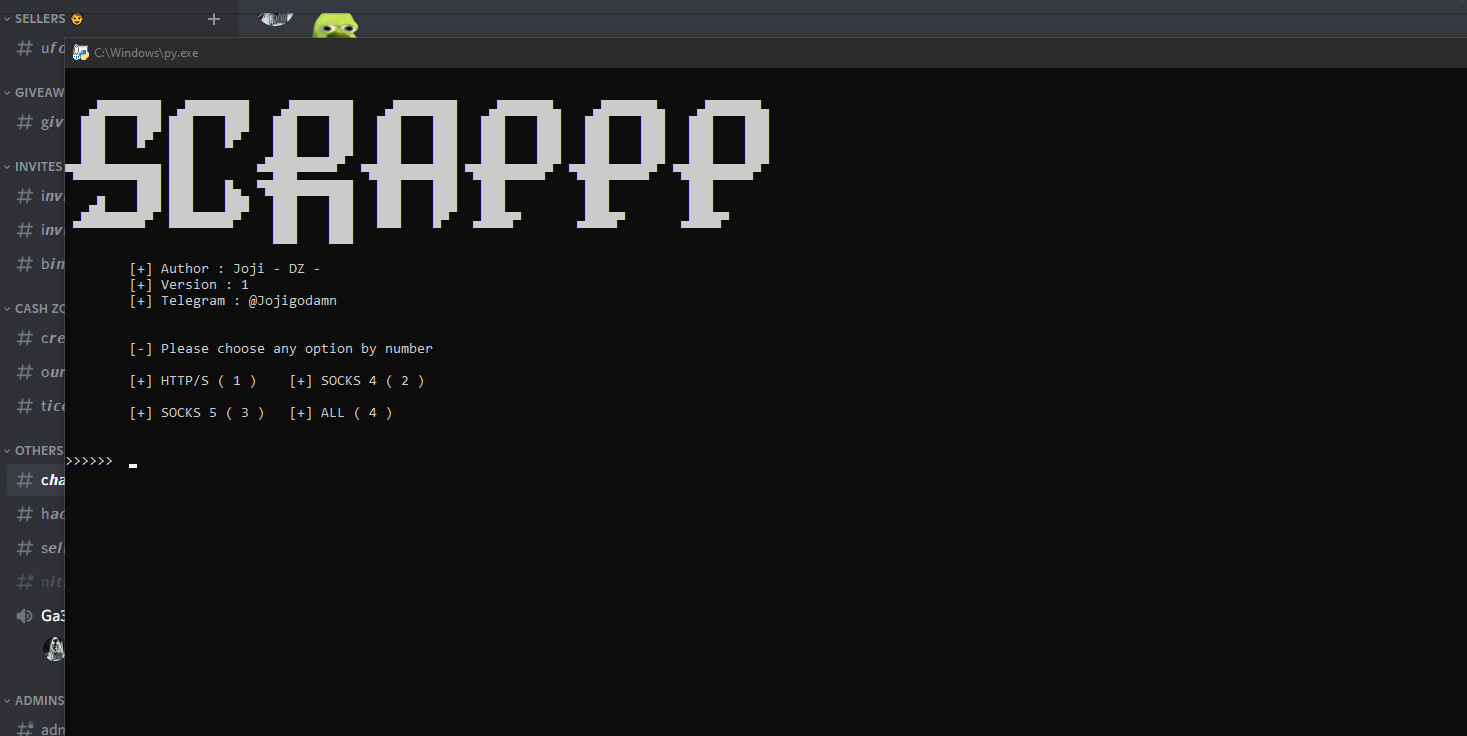

About the script
!!! READ THIS
the script sometimes crash i dont really know why but it STILL WORKING AND YOU CAN USE IT
Contacts
Telegram : @Jojigodamn
Discord : Joji#0082
 2 Nov 16, 2021
2 Nov 16, 2021
 2 Dec 13, 2021
2 Dec 13, 2021
 1 Nov 28, 2021
1 Nov 28, 2021
 1 Jan 6, 2022
1 Jan 6, 2022

 326 Dec 15, 2022
326 Dec 15, 2022
 7 Nov 27, 2022
7 Nov 27, 2022
 299 Dec 15, 2022
299 Dec 15, 2022

 4.8k Jan 4, 2023
4.8k Jan 4, 2023
 87 Jan 6, 2023
87 Jan 6, 2023


 1.1k Dec 17, 2022
1.1k Dec 17, 2022
 1 Feb 11, 2022
1 Feb 11, 2022
 3 Jun 04, 2022
3 Jun 04, 2022
 1 Nov 30, 2021
1 Nov 30, 2021
 3 Feb 13, 2022
3 Feb 13, 2022
 3 Feb 13, 2022
3 Feb 13, 2022
 79 Nov 27, 2022
79 Nov 27, 2022
 47 Nov 23, 2022
47 Nov 23, 2022
 16 Sep 17, 2022
16 Sep 17, 2022
 1.8k Dec 31, 2022
1.8k Dec 31, 2022
 1 Dec 13, 2021
1 Dec 13, 2021
 35 Aug 29, 2022
35 Aug 29, 2022
 1 Nov 05, 2021
1 Nov 05, 2021
 3k Jan 04, 2023
3k Jan 04, 2023
 12 Oct 28, 2022
12 Oct 28, 2022
 1 Jan 14, 2022
1 Jan 14, 2022
 3 Jan 02, 2022
3 Jan 02, 2022
 5 Nov 29, 2022
5 Nov 29, 2022
 31 Apr 17, 2022
31 Apr 17, 2022
 2 Dec 23, 2021
2 Dec 23, 2021